

Should American Educators Use Chinese AI Models? A Practical Guide to the Risks and Opportunities
DeepSeek, Qwen, Kimi, and other Chinese AI tools offer powerful capabilities—but concerns about data security, transparency, and political scrutiny make them complicated choices for U.S. schools.


The next time I invite you over to dinner at my house, be sure to examine the artwork on the walls and the decorations throughout the living room, kitchen, and dining room.
You are likely to derive the impression that Chinese culture has played an important role in my life, and that Chinese colleagues have rewarded me for my work with gifts and honors that I proudly display. That impression would be accurate.
You could of course examine my passport for visas and stamps, showing that I have traveled to China many times for work but never for pleasure. And there is my WeChat account, which boasts connections with more than 300 Chinese colleagues.
Given my work in instructional applications of AI, you might reasonably assume that I am a daily user of Chinese AIs and strongly advocate that other educators do the same. Nothing could be further from the truth.
I tread carefully here for three reasons: Data security, informational transparency, and political repercussions.
Here is an analysis of the dominant Chinese large language models (LLMs) and their use cases for American educators. Whether you use them ultimately depends on your tolerance for risk.
The Major Chinese Models
There are a dozen sophisticated technology companies in China, mostly congregated in Hangzhou and Shenzhen, that offer LLMs for public use. Many of these models are released with open weights, allowing developers to run them locally even though the training data and full code are not always public.
I won’t dig into the countless variations of these LLMs available even in the U.S. and will instead focus on the major Chinese models. By way of a familiar example, Claude offers variants such as Haiku, Sonnet, and Opus — different tiers of the same underlying model.
DeepSeek
DeepSeek has rapidly become one of the most discussed models in the U.S. due to its exceptional performance in mathematics, logic, and high-level programming. It is particularly good at reasoning and technical problem-solving, often matching the capabilities of the most advanced Western models while utilizing significantly fewer computational resources. Its ability to handle complex coding tasks and multi-step logical deductions has made it a favorite among developers and researchers looking for high-end intelligence at a lower cost of entry.
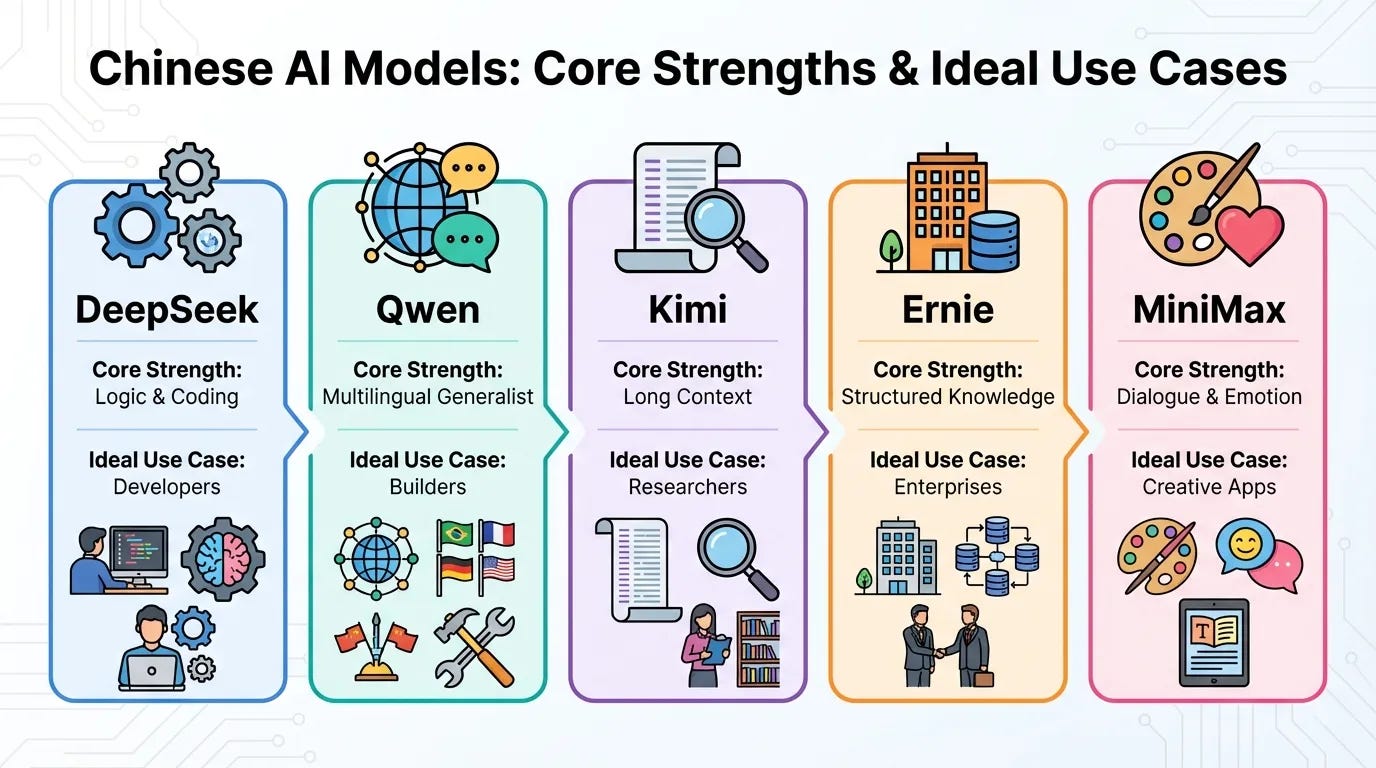
Qwen
Developed by Alibaba, Qwen is a highly versatile generalist model that has gained a strong foothold in the U.S. open-source community. It is particularly good at multilingual tasks and general-purpose utility, consistently ranking at the top of global benchmarks for its ability to follow complex instructions across different languages and domains. Because it is designed to be robust and adaptable, it is frequently used by U.S. developers as a foundational base for building specialized applications, ranging from creative writing to technical documentation.
Kimi
Produced by Moonshot AI, Kimi has distinguished itself by pioneering “long context” capabilities, allowing it to process massive amounts of data in a single session. This model is particularly good at long-form document analysis and summarization, such as reading through entire books, legal filings, or dense research papers to extract specific insights. For U.S. users, its primary value lies in its “memory” — the ability to maintain coherence and accuracy even when the user provides hundreds of thousands of words of background information.
Ernie
As the flagship model from Baidu, Ernie is one of the most established Chinese AI systems, designed for comprehensive knowledge retrieval and enterprise-level stability. It is particularly good at structured data processing and factual knowledge retrieval, drawing from a vast index of information to answer complex queries. While it serves as a general-purpose assistant, its strengths are most apparent in business-logic scenarios and factual research, where a reliable, “heavyweight” baseline for information is required.
MiniMax
MiniMax has gained traction in the U.S. primarily through its success in creative and social-driven consumer applications. This model is particularly good at emotional intelligence and character-driven dialogue, making it highly effective for roleplay, storytelling, and virtual companionship. Unlike models focused strictly on productivity, MiniMax excels at maintaining a specific persona and generating natural, engaging conversation that feels human-like in tone and rhythm.
Creating an account as an American varies widely by platform, as can be seen in the following chart:
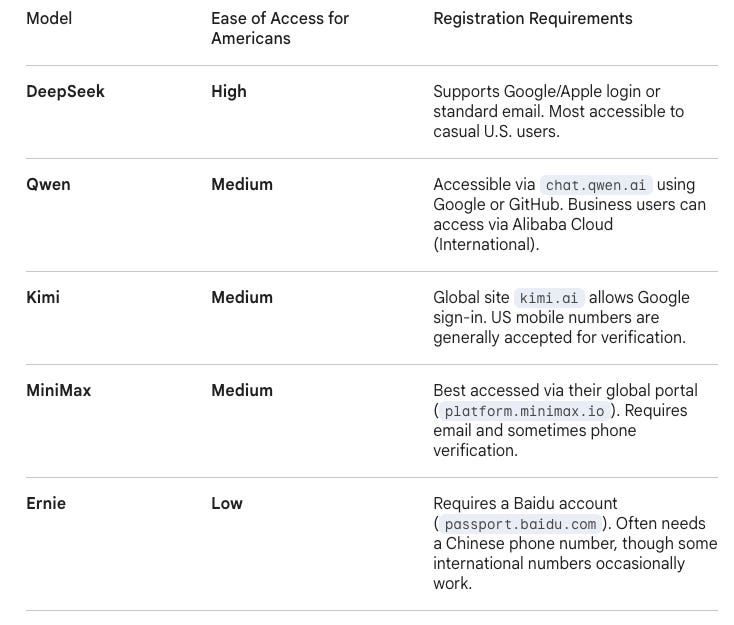
For most American users, DeepSeek and Qwen are the easiest entry points because they offer frictionless Google logins and native-level English. Kimi and MiniMax are specialized tools for long-form research or social creativity, while Ernie remains a powerful but “locked” vault that requires a bit of technical jumping through hoops to access.
Risk Factors for U.S. Educators
Earlier in this blog I identified the three risk factors that inhibit my use of Chinese AIs: Data security, informational transparency, and political repercussions. School districts across the country — most notably in states like Ohio, Texas, and New York — have transitioned from providing guidance to enforcing strict policy. Here is why these specific risk factors matter:
Data Security
Unlike U.S.-based models (Gemini or ChatGPT Enterprise, for instance) that offer Data Shields for education, models like DeepSeek and Kimi often process data directly on servers in China. Early research and security audits in 2025–2026 have raised concerns that some Chinese-hosted AI platforms may expose more user data to external servers than enterprise tools used in U.S. education systems.
If you feed a student’s IEP or an identifiable essay into a tool that lacks a Zero Model Training agreement, you may be exposing yourself or your district to potential FERPA violations. In the 2026 regulatory environment, claiming ignorance of the policy is unlikely to protect an educator if a violation occurs.
2. Informational Transparency
Researchers from Stanford and Princeton recently found that Chinese LLMs — even when responding in English — are significantly more likely to dodge sensitive historical questions or align with specific state-approved narratives.
While all AI has bias ( a topic I explored in this article for Getting Smart), Chinese models often reflect state-approved narratives on sensitive political topics, particularly when queried about modern Chinese history or governance. If a student uses one of these tools for a social studies project, they aren’t getting a neutral summary; they are interacting with an invisible curriculum that hasn’t been vetted by your school board or state standards.
3. Political Repercussions
Public education is inherently political, and in 2026, the scrutiny of foreign-made tech in schools is at an all-time high.
Several U.S. states and federal agencies (including the Navy and NASA) have already issued bans on certain Chinese AI tools. If a parent discovers their child’s data was “sent to a server in Beijing” because of a tool you introduced, it can trigger a community-wide backlash that the district will likely solve by holding the teacher accountable.
Under new 2026 laws (like Ohio HB 96), school districts will soon be required to have formal AI policies. Using a shadow AI tool (one not officially sanctioned) is increasingly viewed as a breach of professional conduct, similar to using an unapproved textbook or software that hasn’t passed a safety audit.
Final Thoughts
Despite my deep affection for Chinese culture and the inspirational work I see happening in Chinese schools, I do not use Chinese AIs for work or pleasure. Yes, I dabbled once to see if the systemic bias identified in their AIs was similar to the systemic bias evident in American AIs. But that experiment is over for me.
While AIs from both countries are built on nearly identical architecture, there are a few functional differences between them. American models like GPT-5 and Claude 4 remain the gold standard for creative nuance and broad general knowledge. Chinese models, on the other hand, have carved out specific functional niches, among them:
Models like DeepSeek and Qwen are often “open-weight.” You can download them and run them locally/offline on school servers. This is a huge win for student data privacy, as no data ever leaves the building.
Qwen 2.5/3.0 is widely considered the king of multilingual support, handling 100+ languages with better cultural nuance for non-Western contexts than many US models.
For a school district looking to integrate AI into every classroom, paying $0.10 per million tokens for DeepSeek vs. $5.00$ for a top-tier US model makes a massive budgetary difference.
Chinese AI models are advancing rapidly and deserve careful attention from educators and researchers. Their open-weight architectures and lower operating costs offer real advantages. But in the current policy environment, American educators must weigh those benefits against serious questions about data governance, transparency, and public trust. For the moment, my own calculation is simple: the risks outweigh the rewards.
This work is licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0). You are free to share and adapt this material with attribution.